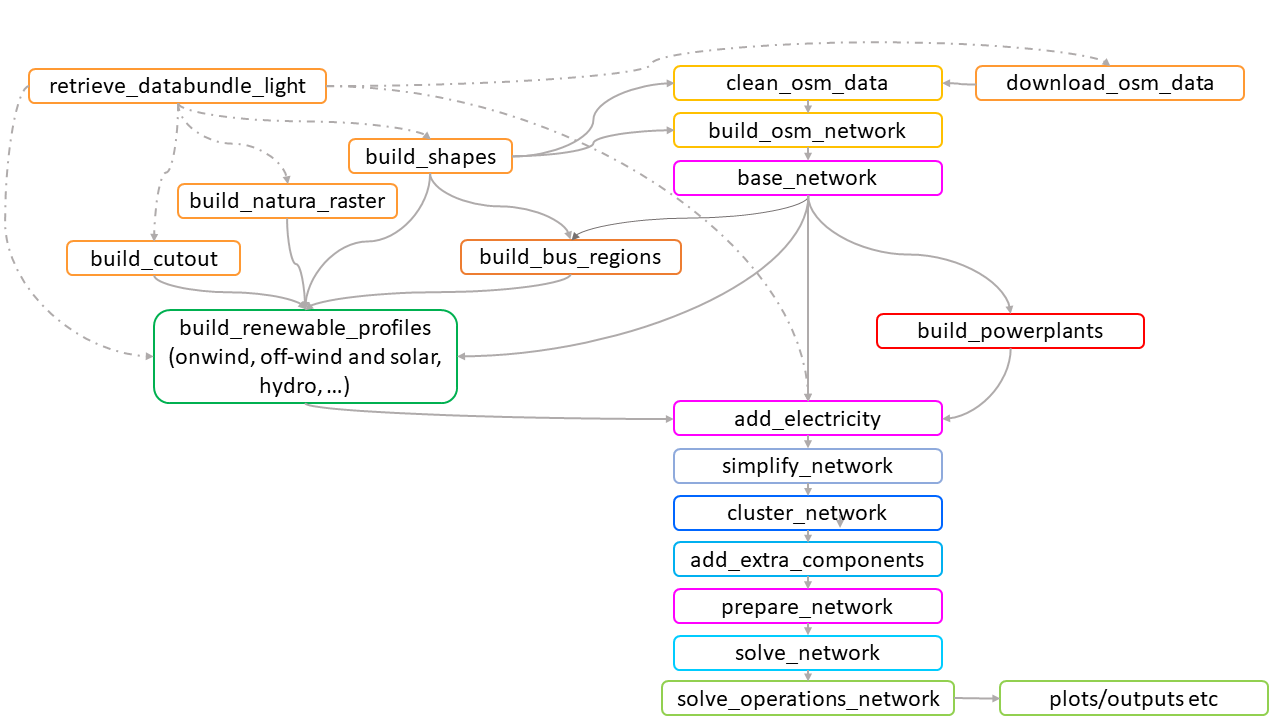
The structure#
The main workflow structure built within PyPSA-Earth is as follows:
1. Download and filter data: first raw input data shall be downloaded. PyPSA-Earth provides automated procedures to successfully download all the needed data from scratch, such as OpenStreetMap data, specific potential of renewable sources, population, GDP, etc. Moreover, raw data shall be filtered to remove non-valid data and normalize the data gathered from multiple sources.
2. Populate data: filtered data are then processed by means of specific methods to derive the main input data of the optimization methods, such as renewable energy production, demand, etc. Just to give an example, when the option is enabled, the renewable energy source potential is transformed into time series for desired locations by using the tool Atlite.
3. Create network model: once the necessary model inputs are drawn, then the network model is developed using PyPSA
4. Solve network: execute the optimization for the desired problem, e.g. dispatch, planning, etc.
5. Summary and plotting: once the model has been solved, produce nice summaries and plotting

The entire execution of the workflow, from point 1 to point 5, relies on the automated workflow management tool Snakemake that iterates the execution of so-called “rules” in an organized way following the input-output chain. The chart of the entire workflow is shown in the following image for a general overview: each block represent a snakemake rule.