Data used by the model#
To properly model any region of the Earth, PyPSA-Earth downloads and fetches different data that are explained in detail in this section. Here we’ll look into architecture of the data workflow while practical hand-ons are given in the Tutorial section.
Two major parts of the energy modeling workflow are preparing of power grid layout and climate inputs. Apart from that, PyPSA-Earth is relying of a number of environmental, economical and technological datasets.
1. Grid topology data#
OpenStreetMap OSM data are used to build power grid topology model. OSM is the biggest crowd-sourced collection of geographic information, which is daily updated and includes geolocation references.
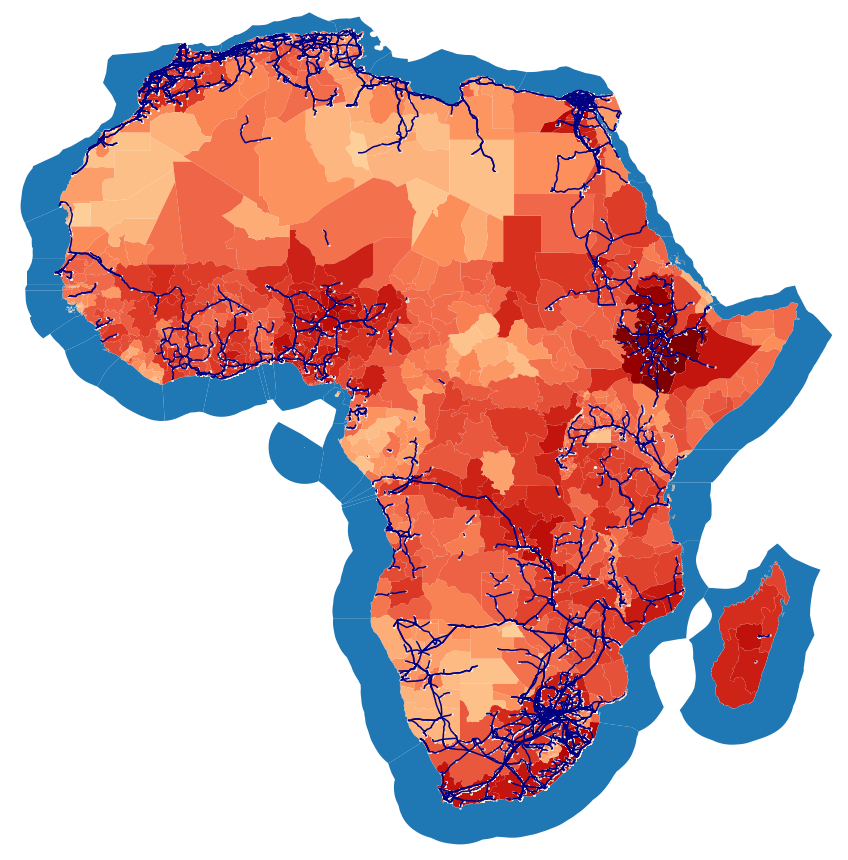
The raw OSM data are being loaded when running the download_osm_data rule and stored in the folder data/osm/{region}/pbf/. Here region denotes a continent, e.g. Africa, or a macro region, e.g. Central America, where the countries of interest belong. The pbf-files contain the entire OSM data for the country; the specific network information related to generators, substations, lines and cables are extracted, cleaned and written as a geojsons in the folder data/osm/{region}/Elements/. All network data (generators, substations, lines and cables) for each country are stored as geojson files.
The cleaned OSM network data that are the output of the osm_data_cleaning rule, which process the raw OSM data to obtain cleaned datasets of all the network assets, namely generators, substations, lines and cables. These data are stored in /resources/osm/ folder.
2. Climate data#
The climate data processing is provided by atlite package. It extracts all the required whether and climate data to generate the time series of renewable potential by generate_renewable_profiles rule. The main data source on climate variables is ERA5 reanalysis.
3. General data#
There are a number datasets applied in PyPSA-Earth to build a realistic model. Original datasets are stored in the data/ folder. Currently we are using the following resources.
Environmental#
copernicus contains the raw data on the land covering as available from the Copernicus database.
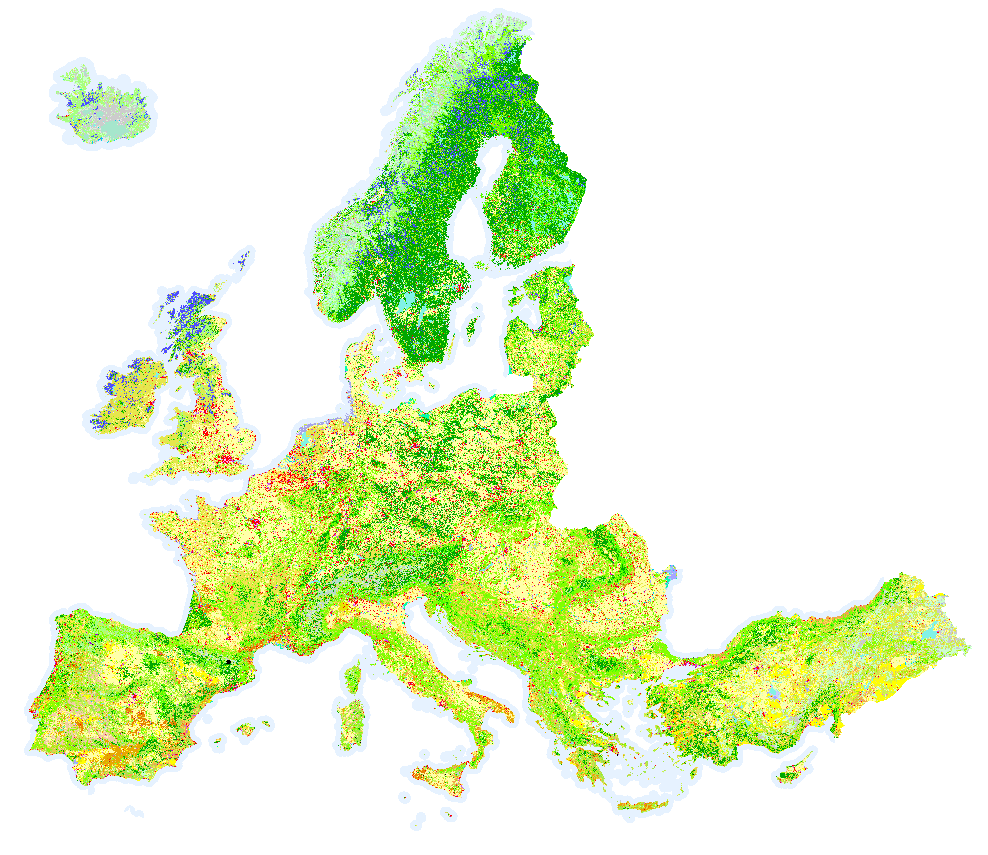
It is used in the build_renewable_profiles rule to quantify what are the land regions available for the installation of renewable resources, e.g. renewable assets may not be installed on arable land
eez is the dataset of the Exclusive Economic Zones (EEZ) available from Marine Regions. This file is used in the rule build_shapes to identify the marine region by country and provide shapes of the maritime regions to be possibly used to estimate off-shore renewable potential, for example.
gebco gridded bathymetric data which can be translated into depths and shapes of underwater terrain.
These data are used in the build_renewable_profiles rule. GEBCO stands for General Bathymetric Chart of the Oceans. It’s curated by a non-profit making organisation which relies largely on the voluntary contributions of an enthusiastic international team of geoscientists and hydrographers.
hydrobasins datasets on watershed boundaries and basins, as available from HydroBASINS. These data are used to estimate the hydropower generation in the build_renewable_profiles rule.
landcover describes the shapes of world protected areas that are needed to identify in what areas no (renewable) assets can be installed. The landcover dataset was used to generate a natura.tiff raster. Nowadays the pre-compiled natura.tiff raster has global coverage, so there is no need to re-calculate it locally to being able run the modeling workflow.
Economical#
costs.csv file contains the default costs of the technologies along with their typical lifetime and efficiency values. The dataset is intended to give a starting point for running the model while regional adjustments may be needed.
gadm folder contains data of the shapes of administrative zones by country (e.g. regions, districts, provinces, …), depending on the level of resolution desired by the configuration file. The data in this folder are automatically populated by the build_shapes rule that download such data from the gadm website.
GDP raster dataset of the Gross Domestic Product (GDP) by arcs of the world, as available from DRYAD.
WorldPop raster dataset of the population by arc as automatically by build_shapes rule from WorldPop
Technological#
eia_hydro_annual_generation.csv contains data on total energy production of existing plants as reported per country by the open US Energy Information Administration EIA platforms. Is used to calibrate the runoff time series are obtained from the global reanalysis data.
4. Pre-calculated datasets#
There are some datasets which were prepared to ensure smooth run of the model. However, they may (and, in some cases, must) be replaced by custom ones.
natura.tiff contains geo-spatial data on location of protected and reserved areas and may be used as a mask to exclude such areas when calculating the renewable potential by build_renewable_profiles rule. The natura flag in the configuration file allows to switch-on this option while presence of the natura.tiff in the resources folder is needed to run the model.
Currently the pre-build file is calculated for Africa, global natura.tiff raster is under development.
electricity demand profiles are provided by PyPSA-Earth as globally hourly demand loads corresponding to Shared Socioeconomic Pathways SSP for 2030, 2040, 2050 and 2100 and weather conditions years of 2011, 2013 and 2018. Pre-calculated data on electricity demand are placed in data/{ssp_scenario_id}/{ssp_year}/era5_2013/{continent_name}.nc folder and loaded automatically during the model run.
The demand time series were modeled by synde package which implements a workflow management system to extract the demand data created with the open source Global-Energy GIS GEGIS package. GEGIS produces hourly demand time series by applying machine learning methods using as predictors temperature profiles, population, GDP.