Configuration#
PyPSA-Earth imports the configuration options originally developed in PyPSA-Eur and here reported and adapted.
The options here described are collected in a config.yaml file located in the root directory.
Users should copy the provided default configuration (config.default.yaml) and amend
their own modifications and assumptions in the user-specific configuration file (config.yaml);
confer installation instructions at Installation.
Note
Credits to PyPSA-Eur developers for the initial drafting of the configuration documentation here reported
Top-level configuration#
version: 0.3.0
tutorial: false
logging:
level: INFO
format: "%(levelname)s:%(name)s:%(message)s"
countries: ["NG", "BJ"]
# Can be replaced by country ["NG", "BJ"], continent ["Africa"] or user-specific region, see more at https://pypsa-earth.readthedocs.io/en/latest/configuration.html#top-level-configuration
enable:
retrieve_databundle: true # Recommended 'true', for the first run. Otherwise data might be missing.
retrieve_cost_data: true # true: retrieves cost data from technology data and saves in resources/costs.csv, false: uses cost data in data/costs.csv
download_osm_data: true # If 'true', OpenStreetMap data will be downloaded for the above given countries
build_natura_raster: false # If True, then an exclusion raster will be build
build_cutout: false
Unit |
Values |
Description |
|
|---|---|---|---|
version |
– |
0.x.x |
Version of PyPSA-Earth |
tutorial |
bool |
{True, False} |
Switch to retrieve the tutorial data set instead of the full data set. |
logging |
|||
– level |
– |
Any of {‘INFO’, ‘WARNING’, ‘ERROR’} |
Restrict console outputs to all infos, warning or errors only |
– format |
– |
Custom format for log messages. See LogRecord attributes. |
|
countries |
– |
Any two-letter country code on earth (60% are working, the team works on making it 100%), any continent, or any user-specific region |
World countries defined by their Two-letter country codes (ISO 3166-1) which should be included in the energy system model. |
enable |
|||
– retrieve_databundle |
bool |
{True, False} |
Switch to retrieve databundle from zenodo via the rule |
– retrieve_cost_data |
bool |
{True, False} |
True: retrieves cost data from technology data and saves in resources/costs.csv, false: uses cost data in data/costs.csv |
– download_osm_data |
bool |
{True, False} |
True: OpenStreetMap data will be downloaded for the above given countries. |
– build_natura_raster |
bool |
{True, False} |
Switch to enable the creation of the raster |
– build_cutout |
bool |
{True, False} |
Switch to enable the building of cutouts via the rule |
custom_rules |
list |
Empty in case no custom rules are needed [], otherwise e.g. [“my_folder/my_rules.smk”] |
Enable the addition of custom rules to the Snakefile |
run#
It is common conduct to analyse energy system optimisation models for multiple scenarios for a variety of reasons, e.g. assessing their sensitivity towards changing the temporal and/or geographical resolution or investigating how investment changes as more ambitious greenhouse-gas emission reduction targets are applied.
The run section is used for running and storing scenarios with different configurations which are not covered by Wildcards. It determines the path at which resources, networks and results are stored. Therefore the user can run different configurations within the same directory. If a run with a non-empty name should use cutouts shared across runs, set shared_cutouts to true.
run:
name: "" # use this to keep track of runs with different settings
shared_cutouts: true # set to true to share the default cutout(s) across runs
Unit |
Values |
Description |
|
|---|---|---|---|
name |
string |
Keeps track of runs with different settings. |
|
shared_cutouts |
bool |
{True, False} |
True: shares the default cutout(s) across runs. Note: value false requires build_cutout to be enabled. |
scenario#
The scenario section is an extraordinary section of the config file
that is strongly connected to the Wildcards and is designed to
facilitate running multiple scenarios through a single command
snakemake -j 1 solve_all_networks
For each wildcard, a list of values is provided. The rule solve_all_networks will trigger the rules for creating results/networks/elec_s{simpl}_{clusters}_ec_l{ll}_{opts}.nc for all combinations of the provided wildcard values as defined by Python’s itertools.product(…) function that snakemake’s expand(…) function uses.
An exemplary dependency graph (starting from the simplification rules) then looks like this:
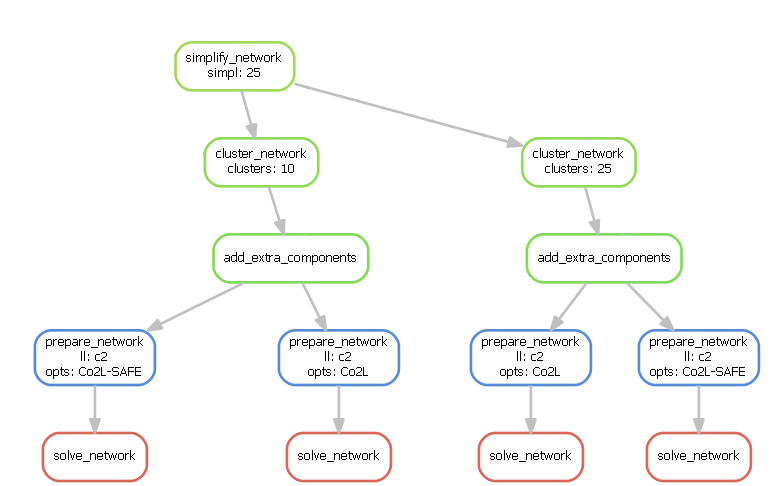
scenario:
simpl: ['']
ll: ['copt']
clusters: [10]
opts: [Co2L-3H]
Unit |
Values |
Description |
|
|---|---|---|---|
simpl |
– |
List of |
|
ll |
– |
List of |
|
clusters |
– |
List of |
|
opts |
– |
List of |
snapshots#
Specifies the temporal range for the historical weather data, which is used to build the energy system model. It uses arguments to pandas.date_range. The date range must be in the past (before 2022). A well-tested year is 2013.
snapshots:
start: "2013-01-01"
end: "2014-01-01"
inclusive: "left" # end is not inclusive
Unit |
Values |
Description |
|
|---|---|---|---|
start |
– |
str or datetime-like; e.g. YYYY-MM-DD |
Left bound of date range. Has to be in the past as weather and demand data for that year is required. |
end |
– |
str or datetime-like; e.g. YYYY-MM-DD |
Right bound of date range. Has to be in the past as weather and demand data for that year is required. |
closed |
– |
One of {None, ‘left’, ‘right’} |
Make the time interval closed to the |
crs#
Defines the coordinate reference systems (crs).
crs:
geo_crs: EPSG:4326 # general geographic projection, not used for metric measures. "EPSG:4326" is the standard used by OSM and google maps
distance_crs: EPSG:3857 # projection for distance measurements only. Possible recommended values are "EPSG:3857" (used by OSM and Google Maps)
area_crs: ESRI:54009 # projection for area measurements only. Possible recommended values are Global Mollweide "ESRI:54009"
Unit |
Values |
Description |
|
|---|---|---|---|
geo_crs |
General geographic projection. Not used for metric measures. |
Recommended value is ‘EPSG:4326’ (used by OSM and Google Maps). |
|
distance_crs |
Projection for distance measurements only. |
Recommended value is ‘EPSG:3857’ (used by OSM and Google Maps). |
|
area_crs |
Projection for area measurements only. |
Recommended value is the Global Mollweide projection ‘ESRI:54009’. |
augmented_line_connection#
If enabled, it increases the connectivity of the network. It makes the network graph k-edge-connected, i.e., if fewer than k edges are removed, the network graph stays connected. It uses the k-edge-augmentation algorithm from the NetworkX Python package.
augmented_line_connection:
add_to_snakefile: false # If True, includes this rule to the workflow
connectivity_upgrade: 2 # Min. lines connection per node, https://networkx.org/documentation/stable/reference/algorithms/generated/networkx.algorithms.connectivity.edge_augmentation.k_edge_augmentation.html#networkx.algorithms.connectivity.edge_augmentation.k_edge_augmentation
new_line_type: ["HVAC"] # Expanded lines can be either ["HVAC"] or ["HVDC"] or both ["HVAC", "HVDC"]
min_expansion: 1 # [MW] New created line expands by float/int input
min_DC_length: 600 # [km] Minimum line length of DC line
Unit |
Values |
Description |
|
|---|---|---|---|
add_to_snakefile |
bool |
{True, False} |
True: includes this rule to the workflow. |
connectivity_upgrade |
int |
{1, 2, 3, …} |
Number k such that the network graph is k-edge-connected. |
new_line_type |
{[“HVAC”], [“HVDC”], [“HVAC”, “HVDC”]} |
Type of expanded lines. |
|
min_expansion |
int or float |
[MW] New created line capacity. |
|
min_DC_length |
int or float |
[km] Minimum line length of HVDC line. |
cluster_options#
Specifies the options to simplify and cluster the network. This is done in two stages, first using the rule simplify_network and then using the rule cluster_network. For more details on this process, see the PyPSA-Earth paper, section 3.7.
cluster_options:
simplify_network:
to_substations: false # network is simplified to nodes with positive or negative power injection (i.e. substations or offwind connections)
algorithm: kmeans # choose from: [hac, kmeans]
feature: solar+onwind-time # only for hac. choose from: [solar+onwind-time, solar+onwind-cap, solar-time, solar-cap, solar+offwind-cap] etc.
exclude_carriers: []
remove_stubs: true
remove_stubs_across_borders: true
p_threshold_drop_isolated: 20 # [MW] isolated buses are being discarded if bus mean power is below the specified threshold
p_threshold_merge_isolated: 300 # [MW] isolated buses are being merged into a single isolated bus if a bus mean power is below the specified threshold
s_threshold_fetch_isolated: 0.05 # [-] a share of the national load for merging an isolated network into a backbone network
cluster_network:
algorithm: kmeans
feature: solar+onwind-time
exclude_carriers: []
alternative_clustering: false # "False" use Voronoi shapes, "True" use GADM shapes
distribute_cluster: ['load'] # Distributes cluster nodes per country according to ['load'],['pop'] or ['gdp']
out_logging: true # When "True", logging is printed to console
aggregation_strategies:
generators: # use "min" for more conservative assumptions
p_nom: sum
p_nom_max: sum
p_nom_min: sum
p_min_pu: mean
marginal_cost: mean
committable: any
ramp_limit_up: max
ramp_limit_down: max
efficiency: mean
Unit |
Values |
Description |
|
|---|---|---|---|
simplify_network |
|||
– to_substations |
bool |
{True, False} |
False: network is simplified to nodes with positive or negative power injection (i.e. substations or offwind connections). |
– algorithm |
{hac, kmeans, modularity} |
Clustering algorithm used in the simplify_network rule. Options available are Hierarchical Agglomerative Clustering (HAC), k-means, or greedy modularity. |
|
– feature |
Str in the format ‘carrier1+carrier2+…+carrierN-X’, where CarrierI can be from {‘solar’, ‘onwind’, ‘offwind’, ‘ror’} and X is one of {‘cap’, ‘time’}. Examples: solar+offwind-cap, solar-time |
Only for Hierarchical Agglomerative Clustering (HAC). Feature(s) used to do the clustering. |
|
– exclude_carriers |
List of Str like [ ‘solar’, ‘onwind’] or empy list [] |
Carriers not considered in the simplify_network rule. Can be any set of carriers (conventional or renewable). |
|
– remove_stubs |
bool |
{True, False} |
True: Stub lines and links, i.e. dead-ends of the network, are sequentially removed from the network. |
– remove_stubs_across_borders |
bool |
{True, False} |
True: Stub lines and links can be removed across borders. |
– p_threshold_drop_isolated |
MW |
positive number |
Isolated buses are discarded if bus mean power is below the p_threshold_drop_isolated. |
– p_threshold_merge_isolated |
MW |
positive number |
Isolated buses are merged into a single isolated bus if bus mean power is below p_threshold_merge_isolated. |
– s_threshold_fetch_isolated |
[-] |
positive number |
Isolated networks are merged into a backbone network of a respective country if the network load comprises a share of the national load less than p_threshold_fetch_isolated. |
cluster_network |
|||
– algorithm |
{hac, kmeans} |
Clustering algorithm used in the cluster_network rule. Options available are Hierarchical Agglomerative Clustering (HAC) or k-means. |
|
– feature |
Str in the format ‘carrier1+carrier2+…+carrierN-X’, where CarrierI can be from {‘solar’, ‘onwind’, ‘offwind’, ‘ror’} and X is one of {‘cap’, ‘time’}. Examples: solar+offwind-cap, solar-time |
Only for Hierarchical Agglomerative Clustering (HAC). Feature(s) used to do the clustering. |
|
– exclude_carriers |
List of Str like [ ‘solar’, ‘onwind’] or empy list [] |
Carriers not considered in the cluster_network rule. Can be any set of carriers (conventional or renewable). |
|
alternative_clustering |
bool |
{True, False} |
False: use Voronoi shapes in the clustering. True: use GADM shapes in the clustering. |
distribute_cluster |
{[‘load’], [‘pop’], [‘gdp’]} |
Distributes cluster nodes per country according to load ([‘load’]), population ([‘pop’]) or GDP ([‘gdp’]). |
|
out_logging |
bool |
{True, False} |
True: Logging is printed to the console. |
aggregation_strategies |
|||
– generators |
|||
– – p_nom |
{min, mean, max, sum} |
Indicates how the p_nom of the aggregated generator is computed from the original p_nom values. For example, if sum, then all values within each cluster are summed to represent the new generator. |
|
– – p_nom_max |
{min, mean, max, sum} |
Indicates how the p_nom_max of the aggregated generator is computed from the original p_nom_max values. |
|
– – p_nom_min |
{min, mean, max, sum} |
Indicates how the p_nom_min of the aggregated generator is computed from the original p_nom_min values. |
|
– – p_min_pu |
{min, mean, max, sum} |
Indicates how the p_min_pu of the aggregated generator is computed from the original p_min_pu values. |
|
– – marginal_cost |
{min, mean, max, sum} |
Indicates how the marginal_cost of the aggregated generator is computed from the original marginal_cost values. |
|
– – commitable |
{any} |
Indicates how the commit status of the aggregated generator is set depending on the original values of the generators. Unit Commitment is currently under development, so should be left to |
|
– – ramp_limit_up |
{min, mean, max, sum} |
Indicates how the ramp_limit_up of the aggregated generator is computed from the original ramp_limit_up values. |
|
– – ramp_limit_down |
{min, mean, max, sum} |
Indicates how the ramp_limit_down of the aggregated generator is computed from the original ramp_limit_down values. |
|
– – efficiency |
{min, mean, max, sum} |
Indicates how the efficiency of the aggregated generator is computed from the original efficiency values. |
build_shape_options#
Specifies the options to build the shapes in which the region of interest (countries) is divided.
build_shape_options:
gadm_layer_id: 1 # GADM level area used for the gadm_shapes. Codes are country-dependent but roughly: 0: country, 1: region/county-like, 2: municipality-like
update_file: false # When true, all the input files are downloaded again and replace the existing files
out_logging: true # When true, logging is printed to console
year: 2020 # reference year used to derive shapes, info on population and info on GDP
nprocesses: 3 # number of processes to be used in build_shapes
worldpop_method: "standard" # "standard" pulls from web 1kmx1km raster, "api" pulls from API 100mx100m raster, false (not "false") no pop addition to shape which is useful when generating only cutout
gdp_method: "standard" # "standard" pulls from web 1x1km raster, false (not "false") no gdp addition to shape which useful when generating only cutout
contended_flag: "set_by_country" # "set_by_country" assigns the contended areas to the countries according to the GADM database, "drop" drops these contended areas from the model
Unit |
Values |
Description |
|
|---|---|---|---|
gadm_layer_id |
{0, 1, 2} |
GADM level area used for the gadm_shapes. Codes are country-dependent but roughly: 0: country, 1: region/county-like, 2: municipality-like. |
|
update_file |
bool |
{True, False} |
True: all input files are downloaded again and replace the existing files. |
out_logging |
bool |
{True, False} |
True: Logging is printed in the console. |
year |
past year; e.g. YYYY |
Reference year used to derive shapes, info on population and info on GDP. |
|
nprocesses |
int |
Number of processes to be used in build_shapes. |
|
worldpop_method |
{“standard”, “api”, false} |
Specifies how population is added to every shape: “standard” pulls from web 1kmx1km raster; “api” pulls from API 100mx100m raster; false (not “false”) no population addition to shape. This is useful when generating only cutout. |
|
gdp_method |
{“standard”, false} |
Specifies how GDP is added to every shape: “standard” pulls from web 1x1km raster; false (not “false”) no gdp addition to shape. This is useful when generating only cutout. |
|
contended_flag |
{“set_by_country”, “drop”} |
Specifies what to do with contended countries: “set_by_country” assigns the contended areas to the countries according to the GADM database; “drop” drops the contended areas from the model. |
clean_osm_data_options#
Specifies the options to clean the OpenStreetMap (OSM) data.
clean_osm_data_options: # osm = OpenStreetMap
names_by_shapes: true # Set the country name based on the extended country shapes
threshold_voltage: 51000 # [V] assets below that voltage threshold will not be used (cable, line, generator, etc.)
tag_substation: "transmission" # Filters only substations with 'transmission' tag, ('distribution' also available)
add_line_endings: true # When "True", then line endings are added to the dataset of the substations
generator_name_method: OSM # Methodology to specify the name to the generator. Options: OSM (name as by OSM dataset), closest_city (name by the closest city)
Unit |
Values |
Description |
|
|---|---|---|---|
names_by_shapes |
bool |
{True, False} |
True: the country name is set based on the extended country shapes. |
threshold_voltage |
V |
Assets below the voltage threshold will not be considered (cable, line, generator, etc.). |
|
tag_substation |
{“transmission”, “distribution”} |
Filters only substations with the corresponding tag (“transmission” or “distribution”). |
|
add_line_endings |
bool |
{True, False} |
True: line endings are added to the dataset of the substations. |
generator_name_method |
{OSM, closest_city} |
Methodology to specify the name of generators. From OpenStreetMap (OSM) or named after the closest city (closest_city). |
|
data_options |
{OSM_only, custom_only, add_custom} |
Method for selecting which type of data is used for lines/cables/substations in the clean_osm_data script. Use OSM (OSM_only), customized (Custom_only), or both data sets (Add_custom). |
build_osm_network#
Specifies the options to build the OpenStreetMap (OSM) network.
build_osm_network: # Options of the build_osm_network script; osm = OpenStreetMap
group_close_buses: true # When "True", close buses are merged and guarantee the voltage matching among line endings
group_tolerance_buses: 5000 # [m] (default 5000) Tolerance in meters of the close buses to merge
split_overpassing_lines: true # When True, lines overpassing buses are splitted and connected to the bueses
overpassing_lines_tolerance: 1 # [m] (default 1) Tolerance to identify lines overpassing buses
force_ac: false # When true, it forces all components (lines and substation) to be AC-only. To be used if DC assets create problem.
Unit |
Values |
Description |
|
|---|---|---|---|
group_close_buses |
bool |
{True, False} |
True: close buses are merged and guarantee the voltage matching among line endings. |
group_tolerance_buses |
m |
Tolerance in meters of the close buses to merge. |
|
split_overpassing_lines |
bool |
{True, False} |
True: lines overpassing buses are splitted and connected to the buses. |
overpassing_lines_tolerance |
m |
Tolerance to identify lines overpassing buses. |
|
force_ac |
bool |
{True, False} |
True: forces all components (lines and substation) to be AC-only. To be used if DC assets create problems. |
base_network#
Specifies the minimum voltage magnitude in the base network and the offshore substations.
base_network:
min_voltage_substation_offshore: 51000 # [V] minimum voltage of the offshore substations
min_voltage_rebase_voltage: 51000 # [V] minimum voltage in base network
Unit |
Values |
Description |
|
|---|---|---|---|
min_voltage_substation_offshore |
V |
Minimum voltage magnitude in offshore substations. |
|
min_voltage_rebase_voltage |
V |
Minimum voltage magnitude in base network. |
load_options#
Specifies the options to estimate future electricity demand (load). Different years might be considered for weather and the socio-economic pathway (GDP and population growth), to enhance modelling capabilities.
load_options:
ssp: "ssp2-2.6" # shared socio-economic pathway (GDP and population growth) scenario to consider
weather_year: 2013 # Load scenarios available with different weather year (different renewable potentials)
prediction_year: 2030 # Load scenarios available with different prediction year (GDP, population)
scale: 1 # scales all load time-series, i.e. 2 = doubles load
Unit |
Values |
Description |
|
|---|---|---|---|
ssp |
Scenario considered for shared socio-economic pathway (GDP and population growth). |
||
weather_year |
past year; e.g. YYYY |
Year from which weather data is taken. Must be a year in the past. Well-tested years are 2011, 2013, and 2018. |
|
prediction_year |
year (can be in the future); e.g. YYYY” |
Year for which the load scenario is computed (GDP and population). Well-tested years are 2030, 2040, 2050, and 2100. |
|
scale |
float |
Scale for all the load time-series or specific countries if specified. For example, ‘2’ doubles the load and ‘NG: 2’ doubles the load only for Nigeria. |
Warning
The snapshots date range (snapshots\start - snapshots\end) must be in the weather_year.
electricity#
Specifies the options for the rule add_electricity. This includes options across several features, including but not limited to: voltage levels, electricity carriers available, renewable capacity estimation, CO2 emission limits, operational reserve, storage parameters. See the table below for more details.
electricity:
base_voltage: 380.
voltages: [132., 220., 300., 380., 500., 750.]
co2limit: 7.75e+7 # European default, 0.05 * 3.1e9*0.5, needs to be adjusted for Africa
co2base: 1.487e+9 # European default, adjustment to Africa necessary
agg_p_nom_limits: data/agg_p_nom_minmax.csv
hvdc_as_lines: false # should HVDC lines be modeled as `Line` or as `Link` component?
automatic_emission: false
automatic_emission_base_year: 1990 # 1990 is taken as default. Any year from 1970 to 2018 can be selected.
operational_reserve: # like https://genxproject.github.io/GenX/dev/core/#Reserves
activate: false
epsilon_load: 0.02 # share of total load
epsilon_vres: 0.02 # share of total renewable supply
contingency: 0 # fixed capacity in MW
max_hours:
battery: 6
H2: 168
extendable_carriers:
Generator: [solar, onwind, offwind-ac, offwind-dc, OCGT]
StorageUnit: [] # battery, H2
Store: [battery, H2]
Link: [] # H2 pipeline
powerplants_filter: (DateOut >= 2022 or DateOut != DateOut)
custom_powerplants: false # "false" use only powerplantmatching (ppm) data, "merge" combines ppm and custom powerplants, "replace" use only custom powerplants
conventional_carriers: [nuclear, oil, OCGT, CCGT, coal, lignite, geothermal, biomass]
renewable_carriers: [solar, onwind, offwind-ac, offwind-dc, hydro]
estimate_renewable_capacities:
stats: "irena" # False, = greenfield expansion, 'irena' uses IRENA stats to add expansion limits
year: 2020 # Reference year, available years for IRENA stats are 2000 to 2020
p_nom_min: 1 # any float, scales the minimum expansion acquired from stats, i.e. 110% of <years>'s capacities => p_nom_min: 1.1
p_nom_max: false # sets the expansion constraint, False to deactivate this option and use estimated renewable potentials determine by the workflow, float scales the p_nom_min factor accordingly
technology_mapping:
# Wind is the Fueltype in ppm.data.Capacity_stats, onwind, offwind-{ac,dc} the carrier in PyPSA-Earth
Offshore: [offwind-ac, offwind-dc]
Onshore: [onwind]
PV: [solar]
Unit |
Values |
Description |
|
|---|---|---|---|
base_voltage |
kV |
float |
Base voltage to which all lines are simplified/aggregated. Simplification preserves transmission capacities. |
voltages |
kV |
A subset of ‘standard’ voltages considered to map OSM-extracted voltages into ‘standard’ linetypes. |
|
co2limit |
\(t_{CO_2-eq}/a\) |
float |
Cap on system total annual carbon dioxide equivalent emissions. |
co2base |
\(t_{CO_2-eq}/a\) |
float |
Reference value of system total annual carbon dioxide equivalent emissions. Used only if relative emission reduction target is specified in |
automatic_emission |
bool |
{True, False} |
True: Emissions are obtained from automatic emission extraction procedure. False: Emissions are obtained manually |
automatic_emission_base_year |
integer |
CO2 emissions of year 1990 from EDGAR category 1A1a (Public electricity and heat production). |
|
agg_p_nom_limits |
file |
path |
Reference to |
hvdc_as_lines |
bool |
{True, False} |
True: HVDC cables are modelled as PyPSA Line components. False: HVDC cables are modeled as PyPSA Link components. |
operational_reserve |
The total operational reserve requirements consist of three components: epsilon_load, epsilon_vres, contingency. See GenX for more details. |
||
– activate |
bool |
{True, False} |
True: Operational reserve requirements are considered in the model. |
– epsilon_load |
float |
[0, 1] |
Share of total load that is required for operational reserve. |
– epsilon_vres |
float |
[0, 1] |
Share of total renewable supply that is required for operational reserve. |
– contingency |
MW |
Operational reserve added as a contigency. For example, 5000 adds 5000 MW to the operational reserve requirements. |
|
max_hours |
|||
– battery |
hours |
Amount of time it takes to fully charge batteries from empty if done at maximum power rate. See PyPSA documentation. It is used in the rule add_extra_components. |
|
– H2 |
hours |
Amount of time it takes to fully charge hydrogen storage from empty if done at maximum power rate. See PyPSA documentation. It is used in the rule add_extra_components. |
|
extendable_carriers |
|||
– Generator |
– |
Any subset of {OCGT,CCGT} |
Adds extendable OCGT and/or CCGT in nodes where gas power plants are located today without capacity limits. Note that solar, onwind, offwind-ac, offwind-dc are extendable by default according to their potentials. It is used in the add_electricity rule. |
– StorageUnit |
– |
Any subset of {battery, H2} |
Adds extendable storage units (battery and/or hydrogen) at every node/bus after clustering without capacity limits and with zero initial capacity. It is used in the add_extra_components rule. |
– Store |
– |
Any subset of {battery,H2} |
Adds extendable storage units (battery and/or hydrogen) at every node/bus after clustering without capacity limits and with zero initial capacity. |
– Link |
– |
Any subset of {H2 pipeline} |
Adds extendable links (H2 pipelines only) at every connection where there are lines or HVDC links without capacity limits and with zero initial capacity. Hydrogen pipelines require hydrogen storage to be modelled as |
powerplants_filter |
– |
use pandas.query strings here, e.g. Country not in [‘Germany’] |
Filter query for the default powerplant database. |
custom_powerplants |
– |
{false, merge, replace} |
Adds custom powerplants from |
conventional_carriers |
– |
Any subset of {nuclear, oil, OCGT, CCGT, coal, lignite, geothermal, biomass} |
List of conventional power plants to include in the model from |
renewable_carriers |
– |
Any subset of {solar, onwind, offwind-ac, offwind-dc, hydro} |
List of renewable power plants to include in the model from |
estimate_renewable_capacities |
|||
– stats |
{“irena” or False} |
Defines which database to use, currently only “irena” is available. “irena” uses IRENA stats to add expansion limits. |
|
– year |
Any year beetween 2000 and 2020 |
Reference year for renewable capacities. Available years for IRENA stats are from 2000 to 2020. |
|
– p_nom_min |
float |
Scales the minimum expansion acquired from stats. For example, 110% of <years>’s capacities is obtained with p_nom_min: 1.1. |
|
– p_nom_max |
float or |
sets the expansion constraint, False to deactivate this option and use estimated renewable potentials determine by the workflow, float scales the p_nom_min factor accordingly. |
|
– technology_mapping |
Maps the technologies defined in ppm.data.Capacity_stats with the carriers in PyPSA-Earth. |
||
– – Offshore |
{‘offwind-ac’, ‘offwind-dc’} |
||
– – Onshore |
{‘onwind’} |
||
– – PV |
{‘solar’} |
Warning
Carriers in conventional_carriers must not also be in extendable_carriers.
lines#
Specifies electricity line parameters.
lines:
ac_types:
132.: "243-AL1/39-ST1A 20.0"
220.: "Al/St 240/40 2-bundle 220.0"
300.: "Al/St 240/40 3-bundle 300.0"
380.: "Al/St 240/40 4-bundle 380.0"
500.: "Al/St 240/40 4-bundle 380.0"
750.: "Al/St 560/50 4-bundle 750.0"
dc_types:
500.: "HVDC XLPE 1000"
s_max_pu: 0.7
s_nom_max: .inf
length_factor: 1.25
under_construction: "zero" # 'zero': set capacity to zero, 'remove': remove, 'keep': with full capacity
Unit |
Values |
Description |
|
|---|---|---|---|
ac_types |
– |
Values should specify a line type in PyPSA for AC lines. Keys should specify the corresponding voltage level (e.g. 220., 300. and 380. kV) |
Specifies line types to assume for the different voltage levels of the target region. Should normally handle voltage levels 220, 300, and 380 kV. |
dc_types |
– |
Values should specify a line type in PyPSA for DC-lines. Keys should specify the corresponding voltage level (e.g. 220., 300. and 380. kV) |
Specifies DC-line types. |
s_max_pu |
– |
Value in [0.,1.] |
Correction factor for line capacities ( |
s_nom_max |
MW |
float |
Global upper limit for the maximum capacity of each extendable line. |
length_factor |
– |
float |
Correction factor to account for the fact that buses are not connected by lines through air-line distance. |
under_construction |
– |
One of {‘zero’: set capacity to zero, ‘remove’: remove completely, ‘keep’: keep with full capacity} |
Specifies how to handle lines which are currently under construction. |
links#
Specifies Link parameters. Links are a fundamental component of PyPSA .
links:
p_max_pu: 1.0
p_nom_max: .inf
under_construction: "zero" # 'zero': set capacity to zero, 'remove': remove, 'keep': with full capacity
Unit |
Values |
Description |
|
|---|---|---|---|
p_max_pu |
– |
Value in [0.,1.] |
Correction factor for link capacities |
p_nom_max |
MW |
float |
Global upper limit for the maximum capacity of each extendable DC link. |
under_construction |
– |
One of {‘zero’, ‘remove’, ‘keep’} |
Specifies how to handle lines which are currently under construction. ‘zero’: set capacity to zero; ‘remove’: remove completely, ‘keep’: keep with full capacity. |
transformers#
Specifies transformers parameters and types.
transformers:
x: 0.1
s_nom: 2000.
type: ""
Unit |
Values |
Description |
|
|---|---|---|---|
x |
p.u. |
float |
Series reactance (per unit, using |
s_nom |
MVA |
float |
Limit of apparent power which can pass through branch. Overwritten if |
type |
– |
Specifies transformer types to assume for the transformers of the ENTSO-E grid extraction. |
atlite#
Define and specify the atlite.Cutout used for calculating renewable potentials and time-series. All options except for features are directly used as cutout parameters.
atlite:
nprocesses: 4
cutouts:
# geographical bounds automatically determined from countries input
cutout-2013-era5:
module: era5
dx: 0.3 # cutout resolution
dy: 0.3 # cutout resolution
# The cutout time is automatically set by the snapshot range. See `snapshot:` option above and 'build_cutout.py'.
# time: ["2013-01-01", "2014-01-01"] # to manually specify a different weather year (~70 years available)
# The cutout spatial extent [x,y] is automatically set by country selection. See `countires:` option above and 'build_cutout.py'.
# x: [-12., 35.] # set cutout range manual, instead of automatic by boundaries of country
# y: [33., 72] # manual set cutout range
Unit |
Values |
Description |
|
|---|---|---|---|
nprocesses |
– |
int |
Number of parallel processes in cutout preparation |
cutouts |
|||
– {name} |
– |
Convention is to name cutouts like |
Name of the cutout netcdf file. The user may specify multiple cutouts under configuration |
– – module |
– |
Subset of {‘era5’,’sarah’} |
Source of the reanalysis weather dataset (e.g. ERA5 or SARAH-2) |
– – x |
° |
Float interval within [-180, 180] |
Range of longitudes to download weather data for. If not defined, it defaults to the spatial bounds of all bus shapes. |
– – y |
° |
Float interval within [-90, 90] |
Range of latitudes to download weather data for. If not defined, it defaults to the spatial bounds of all bus shapes. |
– – time |
Time interval within [‘1979’, ‘2018’] (with valid pandas date time strings) |
Time span to download weather data for. If not defined, it defaults to the time interval spanned by the snapshots. |
|
– – features |
String or list of strings with valid cutout features (‘inlfux’, ‘wind’). |
When freshly building a cutout, retrieve data only for those features. If not defined, it defaults to all available features. |
renewable#
Specifies the options to obtain renewable potentials in every cutout. These are divided in five different renewable technologies: onshore wind (onwind), offshore wind with AC connection (offwind-ac), offshore wind with DC connection (offwind-dc), solar (solar), and hydropower (hydro).
onwind#
renewable:
onwind:
cutout: cutout-2013-era5
resource:
method: wind
turbine: Vestas_V112_3MW
capacity_per_sqkm: 3 # conservative, ScholzPhd Tab 4.3.1: 10MW/km^2
# correction_factor: 0.93
copernicus:
# Scholz, Y. (2012). Renewable energy based electricity supply at low costs:
# development of the REMix model and application for Europe. ( p.42 / p.28)
# CLC grid codes:
# 11X/12X - Various forest types
# 20 - Shrubs
# 30 - Herbaceus vegetation
# 40 - Cropland
# 50 - Urban
# 60 - Bare / Sparse vegetation
# 80 - Permanent water bodies
# 100 - Moss and lichen
# 200 - Open sea
grid_codes: [20, 30, 40, 60, 100, 111, 112, 113, 114, 115, 116, 121, 122, 123, 124, 125, 126]
distance: 1000
distance_grid_codes: [50]
natura: true
potential: simple # or conservative
clip_p_max_pu: 1.e-2
extendable: true
Unit |
Values |
Description |
|
|---|---|---|---|
cutout |
– |
Should be a file name listed in the configuration |
Specifies the directory where the relevant weather data ist stored. |
resource |
|||
– method |
– |
Must be ‘wind’ |
A superordinate technology type. |
– turbine |
– |
One of turbine types included in atlite |
Specifies the turbine type and its characteristic power curve. |
capacity_per_sqkm |
\(MW/km^2\) |
float |
Allowable density of wind turbine placement. |
copernicus |
|||
– grid_codes |
– |
Any subset of the Copernicus Land Cover code list |
Specifies areas based on CLC which generally eligible for AC-connected offshore wind turbine placement. |
– distance |
m |
int |
(Optional) Distance to reserve as uneligible area around ‘distance_grid_codes’ for the renewable technology. |
– distance_grid_codes |
– |
(Optional with ‘distance’) Any subset of the Copernicus Land Cover code list |
Specifies from which a distance of ‘distance’ metres is unavailable as a buffer area. |
natura |
bool |
{true, false} |
Switch to exclude Natura 2000 natural protection areas. Area is excluded if |
potential |
– |
One of {‘simple’, ‘conservative’} |
Method to compute the maximal installable potential for a node; confer Rule build_renewable_profiles |
clip_p_max_pu |
p.u. |
float |
To avoid too small values in the renewables` per-unit availability time series values below this threshold are set to zero. |
extendable |
bool |
{True, False} |
True: In nodes where there is no onwind generation, adds a zero-capacity onwind generator so that onwind is considered in the capacity expansion. It is done in the |
offwind-ac#
offwind-ac:
cutout: cutout-2013-era5
resource:
method: wind
turbine: NREL_ReferenceTurbine_5MW_offshore
capacity_per_sqkm: 2
correction_factor: 0.8855
# proxy for wake losses
# from 10.1016/j.energy.2018.08.153
# until done more rigorously in #153
copernicus:
grid_codes: [80, 200]
natura: true
max_depth: 50
max_shore_distance: 30000
potential: simple # or conservative
clip_p_max_pu: 1.e-2
extendable: true
Unit |
Values |
Description |
|
|---|---|---|---|
cutout |
– |
Should be a file name listed in the configuration |
Specifies the directory where the relevant weather data ist stored. |
resource |
|||
– method |
– |
Must be ‘wind’ |
A superordinate technology type. |
– turbine |
– |
One of turbine types included in atlite |
Specifies the turbine type and its characteristic power curve. |
capacity_per_sqkm |
\(MW/km^2\) |
float |
Allowable density of wind turbine placement. |
correction_factor |
[0., 1.] |
Wind correction factor to account for wake losses. It gets multiplied by the theoretical maximum in the cutout to account for wake losses. |
|
copernicus |
|||
– grid_codes |
– |
Any subset of the Copernicus Land Cover code list |
Specifies areas based on CLC which generally eligible for AC-connected offshore wind turbine placement. |
natura |
bool |
{true, false} |
Switch to exclude Natura 2000 natural protection areas. Area is excluded if |
max_depth |
m |
float |
Maximum sea water depth at which wind turbines can be build. Maritime areas with deeper waters are excluded in the process of calculating the AC-connected offshore wind potential. |
max_shore_distance |
m |
float |
Maximum distance to the shore beyond which wind turbines with AC connections cannot be build. Such areas far away from shore are excluded in the process of calculating the AC-connected offshore wind potential. |
potential |
– |
One of {‘simple’, ‘conservative’} |
Method to compute the maximal installable potential for a node; confer Rule build_renewable_profiles |
clip_p_max_pu |
p.u. |
float |
To avoid too small values in the renewables` per-unit availability time series values below this threshold are set to zero. |
extendable |
bool |
{True, False} |
True: In nodes where there is no offwind-ac generation, adds a zero-capacity offwind-ac generator so that offwind-ac is considered for capacity expansion. It is done in the |
offwind-dc#
offwind-dc:
cutout: cutout-2013-era5
resource:
method: wind
turbine: NREL_ReferenceTurbine_5MW_offshore
# ScholzPhd Tab 4.3.1: 10MW/km^2
capacity_per_sqkm: 3
correction_factor: 0.8855
# proxy for wake losses
# from 10.1016/j.energy.2018.08.153
# until done more rigorously in #153
copernicus:
grid_codes: [80, 200]
natura: true
max_depth: 50
min_shore_distance: 30000
potential: simple # or conservative
clip_p_max_pu: 1.e-2
extendable: true
Unit |
Values |
Description |
|
|---|---|---|---|
cutout |
– |
Should be a file name listed in the configuration |
Specifies the directory where the relevant weather data ist stored. |
resource |
|||
– method |
– |
Must be ‘wind’ |
A superordinate technology type. |
– turbine |
– |
One of turbine types included in atlite |
Specifies the turbine type and its characteristic power curve. |
capacity_per_sqkm |
\(MW/km^2\) |
float |
Allowable density of wind turbine placement. |
correction_factor |
[0., 1.] |
Wind correction factor to account for wake losses. It gets multiplied by the theoretical maximum in the cutout to account for wake losses. |
|
copernicus |
|||
– grid_codes |
– |
Any subset of the Copernicus Land Cover code list |
Specifies areas based on CLC which generally eligible for AC-connected offshore wind turbine placement. |
natura |
bool |
{true, false} |
Switch to exclude Natura 2000 natural protection areas. Area is excluded if |
max_depth |
m |
float |
Maximum sea water depth at which wind turbines can be build. Maritime areas with deeper waters are excluded in the process of calculating the AC-connected offshore wind potential. |
min_shore_distance |
m |
float |
Minimum distance to the shore below which wind turbines cannot be build. Such areas close to the shore are excluded in the process of calculating the AC-connected offshore wind potential. |
potential |
– |
One of {‘simple’, ‘conservative’} |
Method to compute the maximal installable potential for a node; confer Rule build_renewable_profiles |
clip_p_max_pu |
p.u. |
float |
To avoid too small values in the renewables` per-unit availability time series values below this threshold are set to zero. |
extendable |
bool |
{True, False} |
True: In nodes where there is no offwind-dc generation, adds a zero-capacity offwind-dc generator so that offwind-dc is considered for capacity expansion. It is done in the |
solar#
solar:
cutout: cutout-2013-era5
resource:
method: pv
panel: CSi
orientation: latitude_optimal # will lead into optimal design
# slope: 0. # slope: 0 represent a flat panel
# azimuth: 180. # azimuth: 180 south orientation
capacity_per_sqkm: 4.6 # From 1.7 to 4.6 addresses issue #361
# Determined by comparing uncorrected area-weighted full-load hours to those
# published in Supplementary Data to
# Pietzcker, Robert Carl, et al. "Using the sun to decarbonize the power
# sector: The economic potential of photovoltaics and concentrating solar
# power." Applied Energy 135 (2014): 704-720.
correction_factor: 0.854337
copernicus:
grid_codes: [20, 30, 40, 50, 60, 90, 100]
natura: true
potential: simple # or conservative
clip_p_max_pu: 1.e-2
extendable: true
Unit |
Values |
Description |
|
|---|---|---|---|
cutout |
– |
Should be a file name listed in the configuration |
Specifies the directory where the relevant weather data ist stored that is specified at |
resource |
|||
– method |
– |
Must be ‘pv’ |
A superordinate technology type. |
– panel |
– |
One of {‘Csi’, ‘CdTe’, ‘KANENA’} as defined in atlite |
Specifies the solar panel technology and its characteristic attributes. |
– orientation |
use either {latitude_optimal} or options such {slope: 0, azimuth: 180} |
||
– – latitude_optimal |
– |
Atlite function which returns for every raster the optimal slope and azimuth |
|
– – slope |
° |
Realistically any angle in [0., 90.] |
Specifies the tilt angle (or slope) of the solar panel. A slope of zero corresponds to the face of the panel aiming directly overhead. A positive tilt angle steers the panel towards the equator. |
– – azimuth |
° |
Any angle in [0., 360.] |
Specifies the azimuth orientation of the solar panel. South corresponds to 180.°. |
capacity_per_sqkm |
\(MW/km^2\) |
float |
Allowable density of solar panel placement. Value relates to socio-technical acceptable density. |
correction_factor |
– |
float |
A correction factor for the capacity factor (availability) time series. |
copernicus |
|||
– grid_codes |
– |
Any subset of the Copernicus Land Cover code list |
Specifies areas based on CLC which generally eligible for AC-connected offshore wind turbine placement. |
natura |
bool |
{true, false} |
Switch to exclude Natura 2000 natural protection areas. Area is excluded if |
potential |
– |
One of {‘simple’, ‘conservative’} |
Method to compute the maximal installable potential for a node; confer Rule build_renewable_profiles |
clip_p_max_pu |
p.u. |
float |
To avoid too small values in the renewables` per-unit availability time series values below this threshold are set to zero. |
extendable |
bool |
{True, False} |
True: In nodes where there is no solar generation, adds a zero-capacity solar generator so that solar is considered for capacity expansion. It is done in the |
hydro#
hydro:
cutout: cutout-2013-era5
hydrobasins_level: 6
resource:
method: hydro
hydrobasins: data/hydrobasins/hybas_world.shp
flowspeed: 1.0 # m/s
# weight_with_height: false
# show_progress: true
carriers: [ror, PHS, hydro]
PHS_max_hours: 6
hydro_max_hours: "energy_capacity_totals_by_country" # not active
hydro_max_hours_default: 6.0 # (optional, default 6) Default value of max_hours for hydro when NaN values are found
clip_min_inflow: 1.0
extendable: true
normalization:
method: hydro_capacities # 'hydro_capacities' to rescale country hydro production by using hydro_capacities, 'eia' to rescale by eia data, false for no rescaling
year: 2013 # (optional) year of statistics used to rescale the runoff time series. When not provided, the weather year of the snapshots is used
multiplier: 1.1 # multiplier applied after the normalization of the hydro production; default 1.0
Unit |
Values |
Description |
|
|---|---|---|---|
cutout |
– |
Must be ‘europe-2013-era5’ |
Specifies the directory where the relevant weather data ist stored. |
resource |
|||
– method |
Specifies the Atlite method to calculate renewable potential. |
||
– hydrobasin |
Specifies the file location for hydrobasins. They are used to make the runoff calibration, defining a polygon to compute the available water surface using a surface integral. |
||
– flowspeed |
|||
carriers |
– |
Any subset of {‘ror’, ‘PHS’, ‘hydro’} |
Specifies the types of hydro power plants to build per-unit availability time series for. ‘ror’ stands for run-of-river plants, ‘PHS’ represents pumped-hydro storage, and ‘hydro’ stands for hydroelectric dams. |
PHS_max_hours |
h |
float |
Maximum state of charge capacity of the pumped-hydro storage (PHS) in terms of hours at full output capacity |
hydro_max_hours |
h |
Any of {float, ‘energy_capacity_totals_by_country’, ‘estimate_by_large_installations’} |
Maximum state of charge capacity of the pumped-hydro storage (PHS) in terms of hours at full output capacity |
hydro_max_hours_default |
h |
float |
(optional, default 6) Default value of max_hours for hydro plants with missing values |
clip_min_inflow |
MW |
float |
To avoid too small values in the inflow time series, values below this threshold are set to zero. |
extendable |
bool |
{True, False} |
True: In nodes where there is no hydro generation, adds a zero-capacity hydro generator so that hydro is considered for capacity expansion. It is done in the |
normalization |
– |
dict |
When specified, it describes how to normalize hydro time series to adhere to national statistics |
–method |
– |
str |
Data source used to rescale the hydro runoff; option ‘hydro_capacities’ to use the provided ‘data/hydro_capacities.csv’ or ‘eia’ for using the eia file |
–year |
– |
year |
(optional) Specify the desired year to be used for normalization, the default value corresponds to the cutout weather year |
multiplier |
– |
float |
Multiplier factor of the rescaling process (default 1.0) |
costs#
Specifies the cost assumptions of the technologies considered. Cost information is obtained from the config file and the file data/costs.csv, which can also be modified manually.
costs:
year: 2030
version: v0.5.0
rooftop_share: 0.14 # based on the potentials, assuming (0.1 kW/m2 and 10 m2/person)
USD2013_to_EUR2013: 0.7532 # [EUR/USD] ECB: https://www.ecb.europa.eu/stats/exchange/eurofxref/html/eurofxref-graph-usd.en.html
fill_values:
FOM: 0
VOM: 0
efficiency: 1
fuel: 0
investment: 0
lifetime: 25
CO2 intensity: 0
discount rate: 0.07
marginal_cost: # EUR/MWh
solar: 0.01
onwind: 0.015
offwind: 0.015
hydro: 0.
H2: 0.
electrolysis: 0.
fuel cell: 0.
battery: 0.
battery inverter: 0.
emission_prices: # in currency per tonne emission, only used with the option Ep
co2: 0.
Unit |
Values |
Description |
|
|---|---|---|---|
year |
– |
YYYY; e.g. ‘2030’ |
Year for which to retrieve cost assumptions of |
version |
– |
vX.X.X; e.g. ‘v0.1.0’ |
Version of |
rooftop_share |
– |
float |
Share of rooftop PV when calculating capital cost of solar (joint rooftop and utility-scale PV). |
USD2013_to_EUR2013 |
– |
float |
US Dollar-Euro exchange rate. Source: ECB. |
fill_values |
– |
float |
Default values if not specified for a technology in |
marginal_cost |
EUR/MWh |
Keys should be in the ‘technology’ column of |
For the given technologies, assumptions about their marginal operating costs are set to the corresponding value. Optional; overwrites cost assumptions from |
emission_prices |
Specify exogenous prices for emission types listed in |
||
– co2 |
EUR/t |
float |
Exogenous price of carbon-dioxide added to the marginal costs of fossil-fuelled generators according to their carbon intensity. Added through the keyword |
Note
To change cost assumptions in more detail (i.e. other than marginal_cost), consider modifying cost assumptions directly in data/costs.csv as this is not yet supported through the config file.
You can also build multiple different cost databases. Make a renamed copy of data/costs.csv (e.g. data/costs-optimistic.csv) and set the variable COSTS=data/costs-optimistic.csv in the Snakefile.
Note
The marginal costs or in this context variable costs of operating the assets is important for realistic operational model outputs.
It can define the curtailment order of renewable generators, the dispatch order of generators, and the dispatch of storage units.
If not approapriate set, the model might output unrealistic results. Learn more about this in
Parzen et al. 2023 and in
Kittel et al. 2022.
monte_carlo#
Specifies the options for Monte Carlo sampling.
monte_carlo:
# Description: Specify Monte Carlo sampling options for uncertainty analysis.
# Define the option list for Monte Carlo sampling.
# Make sure add_to_snakefile is set to true to enable Monte-Carlo
options:
add_to_snakefile: false # When set to true, enables Monte Carlo sampling
samples: 9 # number of optimizations. Note that number of samples when using scipy has to be the square of a prime number
sampling_strategy: "chaospy" # "pydoe2", "chaospy", "scipy", packages that are supported
seed: 42 # set seedling for reproducibilty
# Uncertanties on any PyPSA object are specified by declaring the specific PyPSA object under the key 'uncertainties'.
# For each PyPSA object, the 'type' and 'args' keys represent the type of distribution and its argument, respectively.
# Supported distributions types are uniform, normal, lognormal, triangle, beta and gamma.
# The arguments of the distribution are passed using the key 'args' as follows, tailored by distribution type
# normal: [mean, std], lognormal: [mean, std], uniform: [lower_bound, upper_bound],
# triangle: [mid_point (between 0 - 1)], beta: [alpha, beta], gamma: [shape, scale]
# More info on the distributions are documented in the Chaospy reference guide...
# https://chaospy.readthedocs.io/en/master/reference/distribution/index.html
# An abstract example is as follows:
# {pypsa network object, e.g. "loads_t.p_set"}:
# type: {any supported distribution among the previous: "uniform", "normal", ...}
# args: {arguments passed as a list depending on the distribution, see the above and more at https://pypsa.readthedocs.io/}
uncertainties:
loads_t.p_set:
type: uniform
args: [0, 1]
generators_t.p_max_pu.loc[:, n.generators.carrier == "onwind"]:
type: lognormal
args: [1.5]
generators_t.p_max_pu.loc[:, n.generators.carrier == "solar"]:
type: beta
args: [0.5, 2]
Unit |
Values |
Description |
|
|---|---|---|---|
options |
|||
add_to_snakemake |
true or false |
Set to true to enable Monte-Carlo |
|
samples |
int |
Defines the number of total sample networks that will be optimized. If the chosen sampling strategy is scipy, then a square of a prime number needs to be chosen. E.g. 49 which is (7^2) |
|
sampling_strategy |
Any subset of {pydoe2, chaospy, scipy} |
Current supported packages to create an experimental design |
|
seed |
int |
Allows experimentation to be reproduced easily |
|
uncertainties |
|||
<any pypsa.object syntax> |
MW/MWh |
Key is a dynamic PyPSA object that allows to access any pypsa object such as loads_t.p_set or the max. wind generation per hour generators_t.p_max_pu.loc[:, n.generators.carrier == “wind”]. Values or bounds are multiplication for each object. |
|
type |
str |
Defines the distribution for the chosen pypsa.object parameter. Distribution can be either uniform, normal, lognormal, triangle, beta or gamma |
|
args |
list |
Defines parameters for the chosen distribution. [mean, std] for normal and lognormal, [lower_bound, upper_bound] for uniform, [mid_point (between 0 - 1)] for triangle, [alpha, beta] for beta, [shape, scale] for gamma |
solving#
Specify linear power flow formulation and optimization solver settings.
options#
solving:
options:
formulation: kirchhoff
load_shedding: true
noisy_costs: true
min_iterations: 4
max_iterations: 6
clip_p_max_pu: 0.01
skip_iterations: true
track_iterations: false
#nhours: 10
Unit |
Values |
Description |
|
|---|---|---|---|
formulation |
– |
Any of {‘angles’, ‘kirchhoff’, ‘cycles’, ‘ptdf’} |
Specifies which variant of linearized power flow formulations to use in the optimisation problem. Recommended is ‘kirchhoff’. Explained in this article. |
load_shedding |
bool |
{‘true’,’false’} |
Add generators with a prohibitively high marginal cost to simulate load shedding and avoid problem infeasibilities. |
noisy_costs |
bool |
{‘true’,’false’} |
Add random noise to marginal cost of generators by \(\mathcal{U}(0.009,0,011)\) and capital cost of lines and links by \(\mathcal{U}(0.09,0,11)\). |
min_iterations |
– |
int |
Minimum number of solving iterations in between which resistance and reactence ( |
max_iterations |
– |
int |
Maximum number of solving iterations in between which resistance and reactence ( |
clip_p_max_pu |
p.u. |
float |
To avoid too small values in the renewables` per-unit availability time series values below this threshold are set to zero. |
skip_iterations |
bool |
{‘true’,’false’} |
Skip iterating, do not update impedances of branches. |
track_iterations |
bool |
{‘true’,’false’} |
Flag whether to store the intermediate branch capacities and objective function values are recorded for each iteration in |
nhours |
– |
int |
Specifies the \(n\) first snapshots to take into account. Must be less than the total number of snapshots. Rather recommended only for debugging. |
solver#
solver:
name: gurobi
threads: 4
method: 2 # barrier (=ipm)
crossover: 0
BarConvTol: 1.e-5
FeasibilityTol: 1.e-6
AggFill: 0
PreDual: 0
GURO_PAR_BARDENSETHRESH: 200
Unit |
Values |
Description |
|
|---|---|---|---|
name |
– |
One of {‘gurobi’, ‘cplex’, ‘cbc’, ‘glpk’, ‘ipopt’}; potentially more possible |
Solver to use for optimisation problems in the workflow; e.g. clustering and linear optimal power flow. |
opts |
– |
Solver specific parameter settings. |
plotting#
Specifies plotting options.
plotting:
map:
figsize: [7, 7]
boundaries: [-10.2, 29, 35, 72]
p_nom:
bus_size_factor: 5.e+4
linewidth_factor: 3.e+3
costs_max: 800
costs_threshold: 1
energy_max: 15000.
energy_min: -10000.
energy_threshold: 50.
vre_techs: ["onwind", "offwind-ac", "offwind-dc", "solar", "ror"]
conv_techs: ["OCGT", "CCGT", "nuclear", "coal", "oil"]
storage_techs: ["hydro+PHS", "battery", "H2"]
load_carriers: ["AC load"]
AC_carriers: ["AC line", "AC transformer"]
link_carriers: ["DC line", "Converter AC-DC"]
tech_colors:
"onwind": "#235ebc"
"onshore wind": "#235ebc"
"offwind": "#6895dd"
"offwind-ac": "#6895dd"
"offshore wind": "#6895dd"
"offshore wind ac": "#6895dd"
"offwind-dc": "#74c6f2"
"offshore wind dc": "#74c6f2"
"hydro": "#08ad97"
"hydro+PHS": "#08ad97"
"PHS": "#08ad97"
"hydro reservoir": "#08ad97"
"hydroelectricity": "#08ad97"
"ror": "#4adbc8"
"run of river": "#4adbc8"
"solar": "#f9d002"
"solar PV": "#f9d002"
"solar thermal": "#ffef60"
"biomass": "#0c6013"
"solid biomass": "#06540d"
"biogas": "#23932d"
"waste": "#68896b"
"geothermal": "#ba91b1"
"OCGT": "#d35050"
"gas": "#d35050"
"natural gas": "#d35050"
"CCGT": "#b20101"
"nuclear": "#ff9000"
"coal": "#707070"
"lignite": "#9e5a01"
"oil": "#262626"
"H2": "#ea048a"
"hydrogen storage": "#ea048a"
"battery": "#b8ea04"
"Electric load": "#f9d002"
"electricity": "#f9d002"
"lines": "#70af1d"
"transmission lines": "#70af1d"
"AC-AC": "#70af1d"
"AC line": "#70af1d"
"links": "#8a1caf"
"HVDC links": "#8a1caf"
"DC-DC": "#8a1caf"
"DC link": "#8a1caf"
"load": "#FF0000"
nice_names:
OCGT: "Open-Cycle Gas"
CCGT: "Combined-Cycle Gas"
offwind-ac: "Offshore Wind (AC)"
offwind-dc: "Offshore Wind (DC)"
onwind: "Onshore Wind"
solar: "Solar"
PHS: "Pumped Hydro Storage"
hydro: "Reservoir & Dam"
battery: "Battery Storage"
H2: "Hydrogen Storage"
lines: "Transmission Lines"
ror: "Run of River"
Unit |
Values |
Description |
|
|---|---|---|---|
map |
|||
– figsize |
– |
[width, height]; e.g. [7,7] |
Figure size in inches. |
– boundaries |
° |
[x1,x2,y1,y2] |
Boundaries of the map plots in degrees latitude (y) and longitude (x) |
– p_nom |
|||
– – bus_size_factor |
– |
float |
Factor by which values determining bus sizes are scaled to fit well in the plot. |
– – linewidth_factor |
– |
float |
Factor by which values determining bus sizes are scaled to fit well in the plot. |
costs_max |
bn Euro |
float |
Upper y-axis limit in cost bar plots. |
costs_threshold |
bn Euro |
float |
Threshold below which technologies will not be shown in cost bar plots. |
energy_max |
TWh |
float |
Upper y-axis limit in energy bar plots. |
energy_min |
TWh |
float |
Lower y-axis limit in energy bar plots. |
energy_threshold |
TWh |
float |
Threshold below which technologies will not be shown in energy bar plots. |
tech_colors |
– |
carrier -> HEX colour code |
Mapping from network |
nice_names |
– |
str -> str |
Mapping from network |